网络
跨域
同源
协议、主机、端口
解决
CORS(跨域资源共享)是一种机制: Access-Control-Allow-Origin/Methods/Headers: 允许的域名
代理服务器
JSONP
// CORS
let _ctx = ctx.httpGateway
_ctx.addResponseHeader('Access-Control-Allow-Origin', '*')
_ctx.addResponseHeader('Access-Control-Allow-Methods', 'GET, POST, PUT, DELETE')
_ctx.addResponseHeader('Access-Control-Allow-Headers', 'Content-Type')服务端需要想客户端也发送cookie的情况,需要服务器端也返回Access-Control-Allow-Credentials: true响应头信息。
其他
简单请求
满足以下条件的请求即为简单请求:
- 请求方法:GET、POST、HEAD
- 除了以下的请求头字段之外,没有自定义的请求头
Accept Accept-Language Content-Language Content-Type DPR Downlink Save-Data Viewport-Width Width - Content-Type的值只有以下三种 (Content-Type一般是指在post请求中,get请求中设置没有实际意义)
text/plain multipart/form-data application/x-www-form-urlencoded
复杂请求
非简单请求即为复杂请求。复杂请求我们也可以称之为在实际进行请求之前,需要发起预检请求的请求。
https & http
单向认证
单向认证流程中,服务器端保存着公钥证书和私钥两个文件,整个握手过程如下:
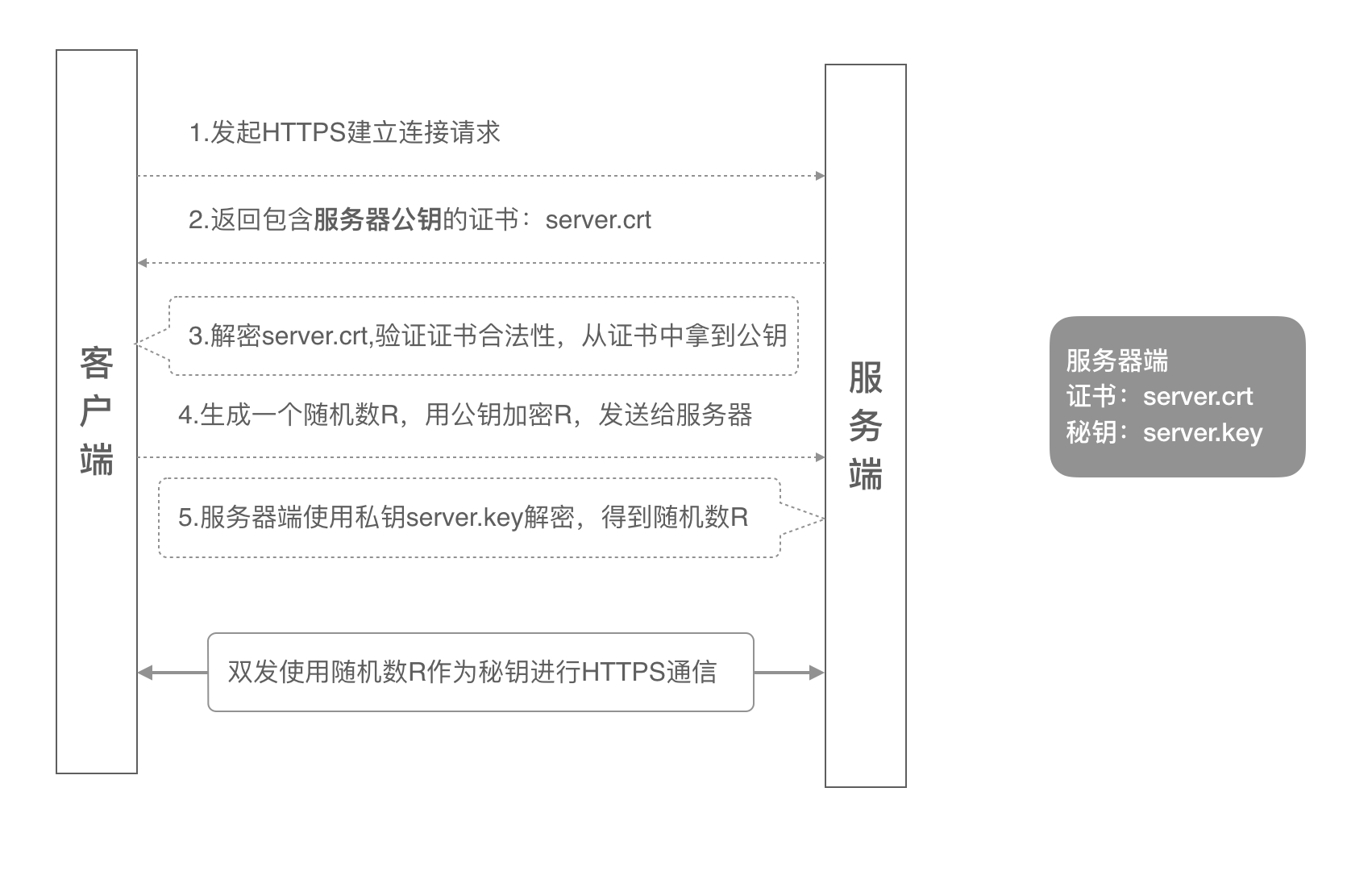
- 客户端发起https请求,并带上SSL协议版本信息到服务端;
- 服务端将证书下发给客户端;
- 客户端收到后,取出证书中的公钥;
- 客户端生成一个随机数:密钥R,用刚才的公钥加密后,发送给服务器;
- 服务器用私钥解密后,得到密钥R;
- 后面通信就用这个密钥R
双向认证

和单向的区别在于,
- 客户端会传递客户端证书给服务端,拿到客户端公钥;
- 客户端将支持的加密方案传给服务端;
- 服务端确定加密方案后,用客户端公钥加密后下发;
- 客户端私钥解密加密方案,生成一个随机数:密钥R。用刚才的公钥加密后,发送给服务器;
SSL证书
SSL证书在一个数据文件中包括以下信息:
- 针对其颁发证书的域名
- 证书颁发给哪一个人、组织或设备
- 证书由哪一证书颁发机构颁发 (证书颁发机构(CA))
- 证书颁发机构的数字签名
- 关联的子域
- 证书的颁发日期
- 证书的到期日期
- 公钥(私钥为保密状态)
数据完整性-摘要算法
实现完整性的手段主要是摘要算法,也就是常说的散列函数 SHA-2、哈希函数
可以理解成一种特殊的压缩算法,它能够把任意长度的数据“压缩”成固定长度、而且独一无二的“摘要”字符串,就好像是给这段数据生成了一个数字“指纹”
计算散列前后是否一致即可;
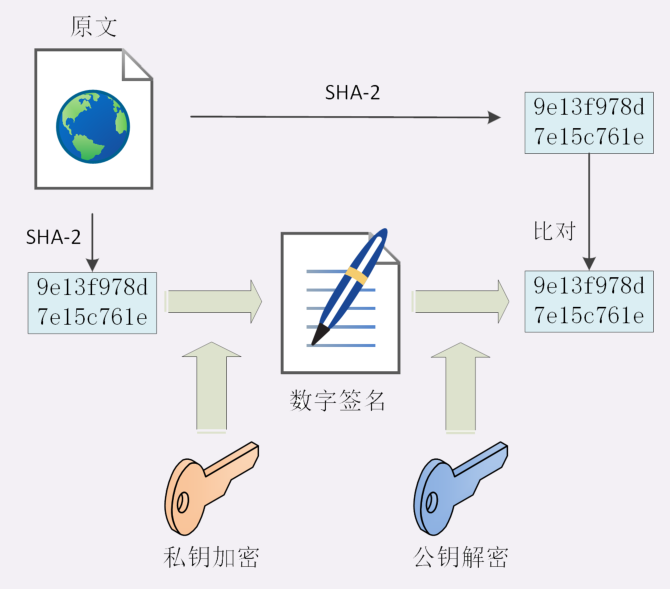
身份验证-数字签名
原理其实很简单,就是用私钥加密,公钥解密
将计算的摘要用私钥加密成数字签名发送过去,接收方公钥解密,对比收到的摘要和解密数字签名的结果对比,即可证明是你发的,应该只有你有对应的私钥。
CA验证机构
黑客可以伪造私钥和公钥。因此需要一个可信赖的第三方机构。
当自己生成SSL证书,会被浏览器提醒不安全。
CA 包括将序列号、用途、颁发者、有效时间等等,打成一个包再用自己的私钥签名,完整地证明各种信息,形成“数字证书”。
接到证书的客户端用数字证书认证机构的公开密钥,对那张证书上的数字签名进行验证,一旦验证通过,则证明没问题。
总结
在HTTP的基础上加入了TLS/SSL协议,结合数字证书、摘要算法和数字签名等,保障了传输的安全。
在请求之前,会客户端服务端会先用非对称加密,实现身份认证和密钥R协商;
后用对称加密:采用协商的密钥对数据加密
http缓存
强缓存
没到服务端,所以直接返回200。
在chrome浏览器中返回的200状态会有两种情况: 1、from memory cache (从内存中获取/一般缓存使用频率较高的js、图片、字体等资源)
2、from disk cache (从磁盘中获取/一般缓存用频率较低的js、css等资源)
这两种情况是chrome自身的一种缓存策略,这也是为什么chrome浏览器响应的快的原因。其他浏览返回的是已缓存状态,没有标识是从哪获取的缓存。
无法获取到修改后的数据? 在修改后的资源加上随机数,确保不会从缓存中取。
Pragma
兼容http/1.0。
cache-control
- no-cache 不用强缓存,而是强制走协商缓存验证。
- no-store 不使用任何缓存。
- public 表明响应可以被任何对象(包括:发送请求的客户端,代理服务器,等等)缓存
- private 表明响应只能被单个用户缓存,不能作为共享缓存(即代理服务器不能缓存它)
max-age=<seconds>设置缓存存储的最大秒数
Expires
过期时间。
存在问题:客户端与服务端时间不一致
协商缓存
返回304。
协商缓存的执行流程是这样的:
- 当浏览器第一次向服务器发送请求时,会在响应头中返回协商缓存的头属性:ETag和Last-Modified,其中ETag返回的是一个hash值,Last-Modified返回的是GMT格式的最后修改时间。
- 然后浏览器在第二次发送请求的时候,会在请求头中带上与ETag对应的If-Not-Match,其值就是响应头中返回的ETag的值,Last-Modified对应的If-Modified-Since。
- 服务器在接收到这两个参数后会做比较,如果返回的是304状态码,则说明请求的资源没有修改,浏览器可以直接在缓存中取数据,否则,服务器会直接返回数据。
其他
Date/Age
响应报文中的 Date 和 Age 字段:区分其收到的资源是否命中了代理服务器的缓存。
Date 理所当然是原服务器发送该资源响应报文的时间(GMT格式),如果你发现 Date 的时间与“当前时间”差别较大,或者连续F5刷新发现 Date 的值都没变化,则说明你当前请求是命中了代理服务器的缓存。
Age 也是响应报文中的首部字段,它表示该文件在代理服务器中存在的时间(秒),如文件被修改或替换,Age会重新由0开始累计。
html 设置缓存
<meta http-equiv="Cache-Control" content="no-cache, no-store, must-revalidate" />TCP 三次握手&四次挥手
http基于TCP,TCP是一种面向连接的协议,它需要在发送数据之前建立一个可靠的连接,并在发送完数据后断开这个连接。
TCP6个标志位
SYN(synchronous建立联机) 、ACK(acknowledgement 确认)、 PSH(push传送)、FIN(finish结束)、RST(reset重置)、URG(urgent紧急)
三次握手

干嘛非要三次,两次不香吗?
确认客户端的接收能力。
如果第二次握手完成后,服务端就直接发送东西给客户端,这时候客户端却断开了连接,服务端却不知道,依然给客户端发送东西,那客户端肯定是无法接收到服务端发来的东西的,由此可见,三次握手必不可少
四次挥手
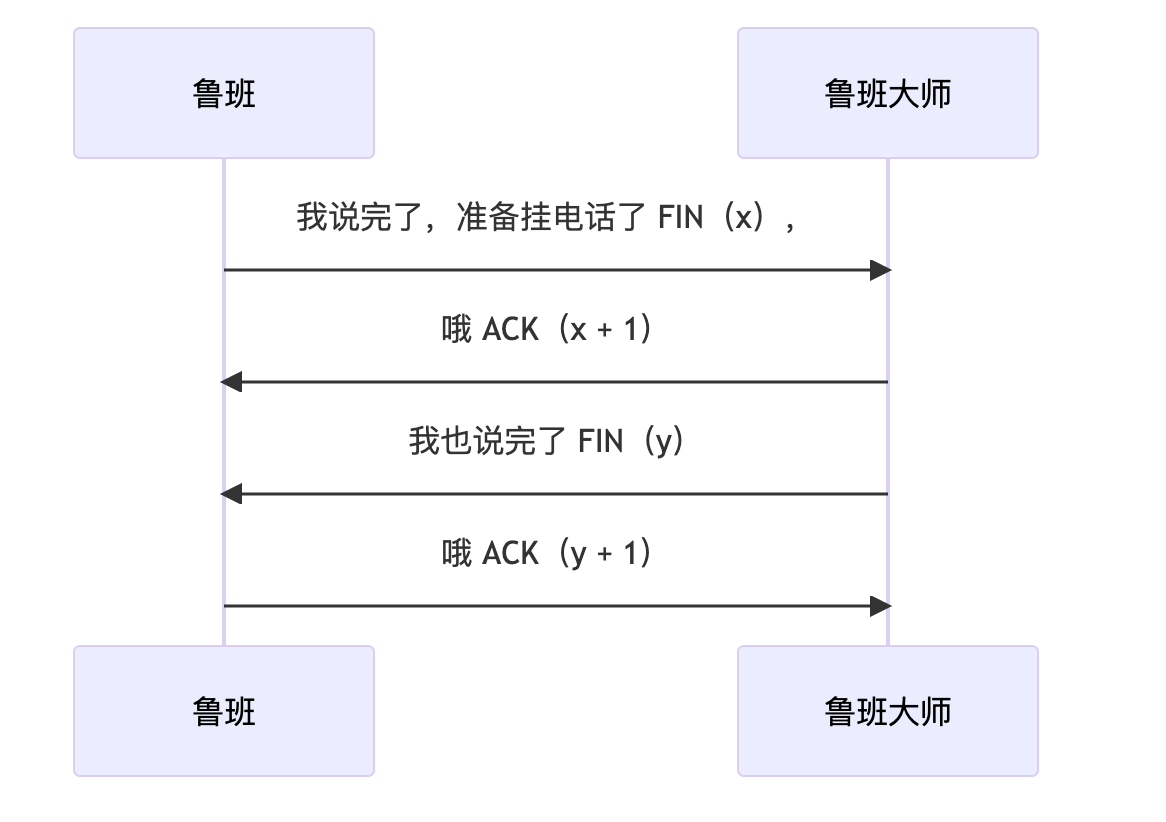
为什么建立连接是三次握手,而关闭连接却是四次挥手呢?
客户端谁再见,只是表明他不再发送信息了,并不表示不再接收信息。可能还有服务端未发送完的。
就像我们关闭浏览器时(1),浏览器收到并提示还有下载进度(2),要等浏览器下载完后通知我们(3),我们才最终关闭浏览器(4)
UDP
UDP(用户数据报协议)没有类似TCP的三次握手和四次挥手的过程。这是因为UDP是一种无连接的协议,它不需要在发送数据之前建立一个连接,也不需要在发送完数据后断开连接。UDP只是简单地将数据报发送出去,而不关心数据报是否能够到达目的地。这使得UDP比TCP更快,但也更不可靠。
WebSocket
一种网络传输协议,位于OSI模型的应用层。可在单个TCP连接上进行全双工通信,能更好的节省服务器资源和带宽并达到实时通迅
客户端和服务器只需要完成一次握手,两者之间就可以创建持久性的连接,并进行双向数据传输。
引入ws和wss分别代表明文和密文的websocket协议,且默认端口使用80或443,几乎与http一致。
DNS